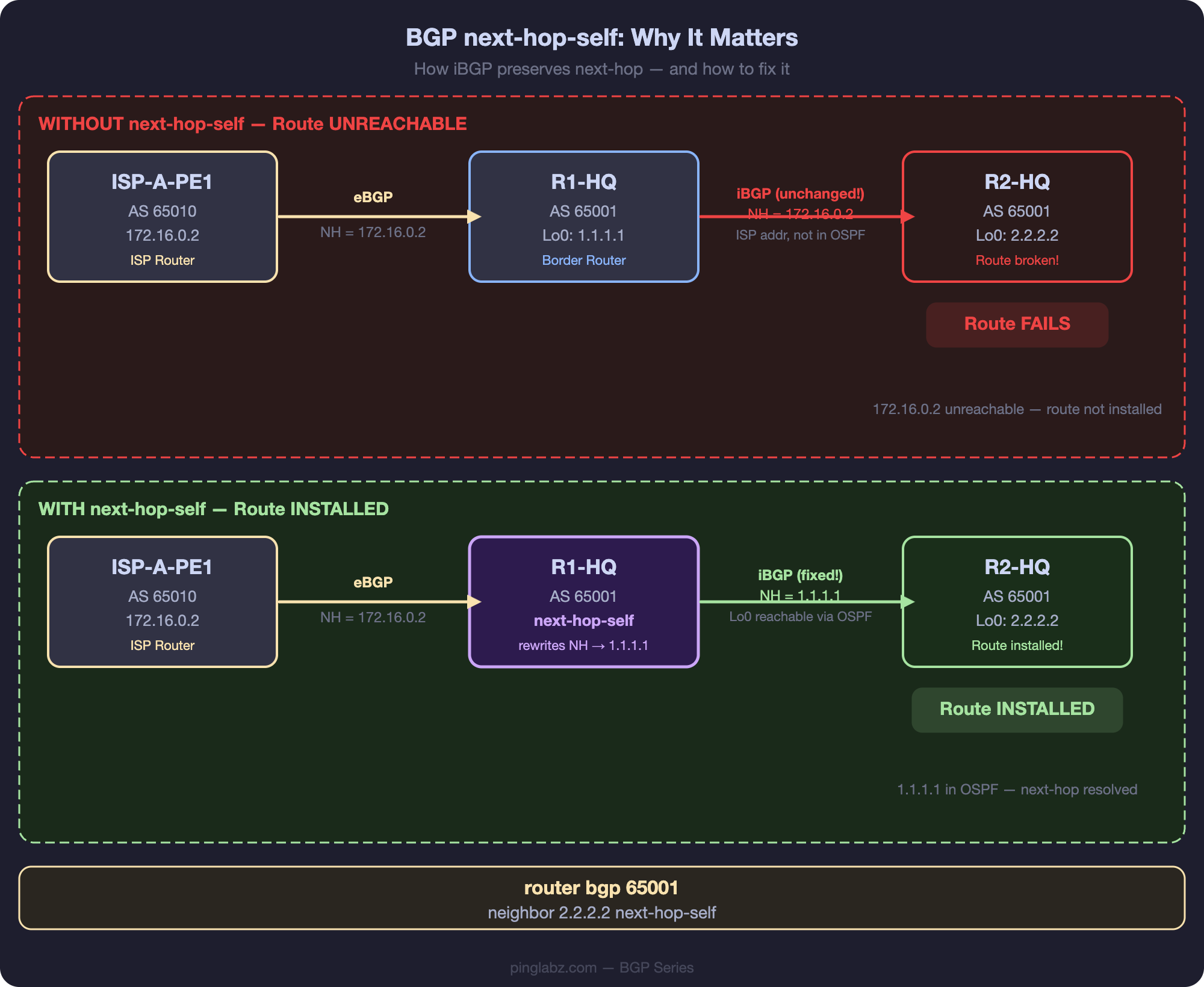
One of the most common iBGP issues is a route that appears in the BGP table but never makes it into the IP routing table. The culprit is almost always the same: the BGP next-hop is unreachable. This happens because iBGP, unlike eBGP, does not change the next-hop attribute when advertising routes to peers within the same AS. The next-hop-self command fixes this — but understanding why it's needed and when to apply it is more important than just blindly adding it everywhere.
The Problem
In our PingLabz BGP Lab, R1-HQ (AS 65001) learns the prefix 100.64.0.0/18 from ISP-A-PE1 via eBGP. The next-hop is set to 172.16.0.2 (ISP-A's interface on the transit link).
R1-HQ# show ip bgp 100.64.0.0/18
BGP routing table entry for 100.64.0.0/18, version 8
Paths: (1 available, best #1, table default)
65010
172.16.0.2 from 172.16.0.2 (203.0.113.1)
Origin IGP, metric 0, localpref 100, valid, external, bestWhen R1-HQ advertises this route to R2-HQ over iBGP, the next-hop stays as 172.16.0.2. R2-HQ receives the route:
R2-HQ# show ip bgp 100.64.0.0/18
BGP routing table entry for 100.64.0.0/18, version 0
Paths: (1 available, no best path)
65010
172.16.0.2 (inaccessible) from 1.1.1.1 (1.1.1.1)
Origin IGP, metric 0, localpref 100, valid, internal
rx pathid: 0, tx pathid: 0Notice: (inaccessible) and no best path. The route exists in R2-HQ's BGP table but is not valid for path selection because 172.16.0.2 isn't in R2-HQ's routing table. R2-HQ has no direct connection to the ISP-A transit link and no route to that /30 subnet.
The route will NOT appear in show ip route. Traffic to 100.64.0.0/18 will be dropped or follow a less-specific default route.
The Fix
On R1-HQ, add next-hop-self for the iBGP peer:
R1-HQ(config)# router bgp 65001
R1-HQ(config-router)# neighbor 2.2.2.2 next-hop-selfNow when R1-HQ advertises the route to R2-HQ, it changes the next-hop to its own loopback (1.1.1.1):
R2-HQ# show ip bgp 100.64.0.0/18
BGP routing table entry for 100.64.0.0/18, version 12
Paths: (1 available, best #1, table default)
65010
1.1.1.1 from 1.1.1.1 (1.1.1.1)
Origin IGP, metric 0, localpref 100, valid, internal, best
rx pathid: 0, tx pathid: 0x0Now the next-hop is 1.1.1.1, which R2-HQ can reach via OSPF. The route is valid, best, and installed in the routing table.
Why Doesn't iBGP Change the Next-Hop Automatically?
It seems like a design flaw, but there's a reason. In networks where all BGP speakers are on a shared segment (like an IXP or a large LAN), the internal routers can reach the external next-hop directly. Preserving the original next-hop avoids an extra hop through the border router. The traffic goes directly from the internal router to the external next-hop across the shared segment.
In practice, this topology is uncommon in enterprise networks. Almost every enterprise deployment needs next-hop-self on border routers for their iBGP peers.
next-hop-self vs next-hop-self all
Standard next-hop-self only changes the next-hop for eBGP-learned routes when advertising to iBGP peers. It does NOT change the next-hop for routes learned from other iBGP peers.
The all keyword changes the next-hop for ALL routes, including iBGP-learned ones:
R1-HQ(config-router)# neighbor 2.2.2.2 next-hop-self allThis is typically only needed in route reflector environments where reflected routes might have next-hops from other RR clients. In most cases, standard next-hop-self (without all) is sufficient.
Alternative: Redistribute the Transit Link into IGP
Instead of next-hop-self, you could include the transit link subnet (172.16.0.0/30) in OSPF so that R2-HQ has a route to 172.16.0.2. This works but leaks ISP-facing subnets into your IGP, which is generally undesirable — especially if you have many transit links. next-hop-self is the cleaner solution.
Verification Commands
! Confirm next-hop-self is configured
R1-HQ# show ip bgp neighbors 2.2.2.2 | include next hop
Route map for outgoing advertisements is *not set*
NEXT_HOP is always this router for eBGP paths
! Verify R2-HQ sees the corrected next-hop
R2-HQ# show ip bgp 100.64.0.0/18
...
1.1.1.1 from 1.1.1.1 (1.1.1.1)
Origin IGP, metric 0, localpref 100, valid, internal, best
! Confirm route is in the IP routing table
R2-HQ# show ip route 100.64.0.0
Routing entry for 100.64.0.0/18
Known via "bgp 65001", distance 200, metric 0
Tag 65010, type internal
Last update from 1.1.1.1 02:15:33 ago
Routing Descriptor Blocks:
* 1.1.1.1, from 1.1.1.1, 02:15:33 ago
Route metric is 0, traffic share count is 1
AS Hops 1Troubleshooting
| Symptom | Cause | Fix |
|---|---|---|
| BGP route shows "(inaccessible)" next-hop on iBGP peer | next-hop-self not configured on the border router | Add neighbor [peer] next-hop-self on the border router for all iBGP peers. |
| next-hop-self configured but next-hop still shows external IP | Configuration was added after the session was established; routes need to be re-advertised | Do a soft reset: clear ip bgp [peer] soft out to re-advertise with the new next-hop. |
| Route valid in BGP table but not in routing table | Another route with lower AD exists for the same prefix (e.g., OSPF at AD 110 vs iBGP at AD 200) | Check show ip route [prefix] to see which protocol is winning. This is expected behavior. |
Key Takeaways
- iBGP preserves the original eBGP next-hop by default. This causes routes to be marked "inaccessible" on internal routers that can't reach the external next-hop.
next-hop-selfon border routers is the standard fix — it changes the next-hop to the border router's own address (usually a loopback) when advertising to iBGP peers.- The original behavior exists for shared-segment scenarios (IXPs), but enterprise networks almost always need next-hop-self.
- After adding
next-hop-selfto an existing session, do a soft outbound reset to trigger re-advertisement with the corrected next-hop. - Always verify with
show ip bgp [prefix]on the receiving router — look for "(inaccessible)" or "no best path" as indicators of next-hop issues.